

Luka Nenadic
Doctoral Student, ETH Zurich Center for Law & Economics
Luka Nenadic is a doctoral student at ETH Zurich’s Center for Law & Economics and a former recognised student at the Oxford Internet Institute.

How contract generators, platforms, and AI are reshaping consumer contracts
Setting the scene
From small businesses selling through Shopify to bloggers using WordPress, many people now draft consumer contracts without ever speaking to a lawyer. They rely on templates, online contract generators, and increasingly AI tools. What was once the preserve of qualified lawyers is becoming automated, standardized, and accessible to the general public. Online platforms acting as private rulemakers are, moreover, promulgating contractual defaults at an unprecedented scale. All of this marks the rise of a new era of lawyerless contracting.
From Templates to Contract Generators
Simpler consumer-facing contracts have been written without lawyers for a long time. For example, industry and consumer organizations have long provided templates to their members. While such templates are very useful, they typically offer very little customizability. This lack of personalization and the advent of personal computers sparked the era of automated document assembly systems: software that builds contracts by combining multiple pre-defined legal clauses. More advanced versions, referred to as “contract generators,” became widely available on the internet through businesses such as Rocket Lawyer in the U.S. or LawDepot in the U.K.
Recent studies show that contract generators are widely used in the context of privacy. For one, Pan et al. (2024) reported that 20% of app privacy policies on the Google Play Store were drafted by generators such as Termly or Iubenda. Our own research found that 18% of privacy policies of Swiss websites are generator-produced, with smaller websites being more likely to use such a tool. This emerging line of work reveals both the importance and promises of investigating how different contracts are increasingly written without the help of lawyers.
Platform Republics
Internet platforms are another significant driver of lawyerless contracting. Connecting billions of people and businesses, platforms must decide how their users are allowed to interact with each other. To avoid conflicts and potential liability, platforms set rules governing the contractual relationships between their users. The scale and power of these platforms means that we observe a fundamentally different situation than the mere provision of voluntary templates. In this sense, online platforms act as private rule-makers, i.e., as “Platform Republics.”
In an ongoing project, we analyze app licenses on Apple’s App Store. Apple provides a default license that automatically applies to each app, unless the developer explicitly opts out. It also requires specific mandatory terms to be mentioned in custom licenses. Given the sheer number of app developers and users on the App Store, Apple arguably exerts an even greater influence on the contents of contracts than many formal legal rules do. The platform thus contributes to lawyerless contracting by providing a default contract used by close to a million apps, governing billions of contractual relationships. Unlike contract generators, however, Apple’s default licence pushes lawyerless contracting more towards standardization than individualization.
AI Contract Drafting
If contract generators facilitated customization, and platforms made contractual defaults scalable, AI promises to combine both: individualized, low-cost drafting at a very large scale. Beyond flashy headlines like “Florida man uses ChatGPT to sell his home” and a related experiment run by a journalist from the New York Times, individuals and small businesses are increasingly using chatbots to generate contracts. At the same time, specialized firms like Harvey and Legora offer tailored contract drafting services to lawyers. Because this is still a relatively new phenomenon, empirical evidence on how people actually use AI tools to draft contracts remains scarce. Just as contract generators became publicly available over time, it is conceivable that the tools used primarily by lawyers today will soon be accessible to laypeople. Taken together, contract generators, platforms, and emerging AI tools are ushering in a new era of lawyerless contracting, as visualized in Figure 1.
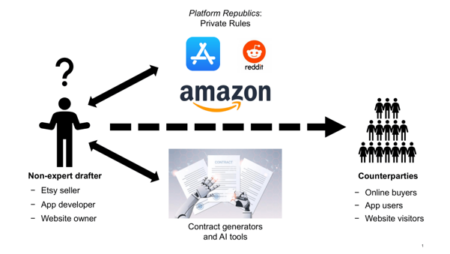
FIGURE 1: New forms of lawyerless contracting in the digital world.
Potential Pitfalls and Policy Implications
This tour d’horizon of how technologies are turbocharging lawyerless contracting demands two important caveats. First, at least for the time being, contract lawyers are not being entirely replaced. While individuals and small businesses may use (platform) templates, contract generators, or AI, deep-pocketed clients still desire a law firm’s seal of approval for high-stakes transactions. Even the brave Floridian home seller and the NYT journalist hired a lawyer to review their contracts. For less complex and more standardized contracts, however, novel drafting technologies may at least considerably reduce the demand for contract lawyers.
Second, and even more importantly, lawyerless contracting involves important trade-offs. On the one hand, laypeople can now access (partly) individualized legal guidance at a fraction of the cost of what a contract lawyer would charge them. On the other hand, the drawbacks can be serious: poorly written or unsuitable clauses can lead to lawsuits, damages, and reputational harm for drafters, while consumers may face unfair, unclear, or unenforceable terms. It is, moreover, equally important to reflect whether current laws and regulations fit the purposes of lawyerless contracts. These questions touch on accountability, liability, consumer protection, and rules on who may lawfully provide legal advice. They thus call for more empirical and doctrinal research to comprehensively assess the impact of lawyerless contracting.
Conclusion and Outlook
So where does all of this leave us? The first key takeaway is that people have drafted contracts from templates, without legal experts, for a very long time. What has changed is that more customizable contract drafting tools have become accessible to the general public, leading to a form of “mass personalization.” Second, we have probably not yet reached the final technological stage of lawyerless contracting. One potential future development could be the use of autonomous agents not only to draft contracts but also to negotiate the underlying agreements. The age of lawyerless contracting is truly at our fingertips.
About the author
Luka Nenadic is a doctoral student at ETH Zurich’s Center for Law & Economics and a former recognised student at the Oxford Internet Institute. He would like to thank Stefan Bechtold, Sandra Wachter, Anna-Lea Schlup, Sara Spinks, and Veena McCoole for their valuable feedback.
The author acknowledges having used large language models to refine the blog post’s language and style. The ideas remain his own.
