
{kind=link}

Vyacheslav W. Polonski
Former DPhil Student
Vyacheslav Polonski an OII DPhil alumnus, specialising in network science and the sociology of the Internet. His research focused on the structural aspects of collective behaviour in online communities.

THE GIST: Would you trust Siri to organise your next family trip? How about allowing Siri to cast your ballot in the next election? The more data we feed into our personalisation algorithms, the better the decisions they make on our behalf. Yet the pace of AI progress brings challenges we must confront. Bias in algorithms can amplify our own biases and deepen social divisions. What is more, AI applications use data from our past actions to anticipate our needs in the future. This is problematic, because it tends to reproduce established patterns of behaviour, providing old answers to new questions. This form of algorithmic determinism is dangerous, because it precludes our need for experimentation and exploration, while ignoring the multiplicity of our identity.
Imagine a typical day in 2020: your personal AI assistant wakes you up with a friendly greeting before preparing your favourite breakfast. During your morning workout, they play new songs that perfectly match your taste. For your commute to work, they’ve already pre-selected a few articles based on the duration of your commute and what you’ve read in the past.
You read the news and remember the presidential elections are coming up. Based on a predicted model that takes into account your previously expressed views and data on other voters in your state, your AI assistant recommends you vote Democrat. A pop-up message on your phone asks whether you want your AI assistant to handle the paperwork and cast the vote on your behalf. You tap “agree” and get on with your life.
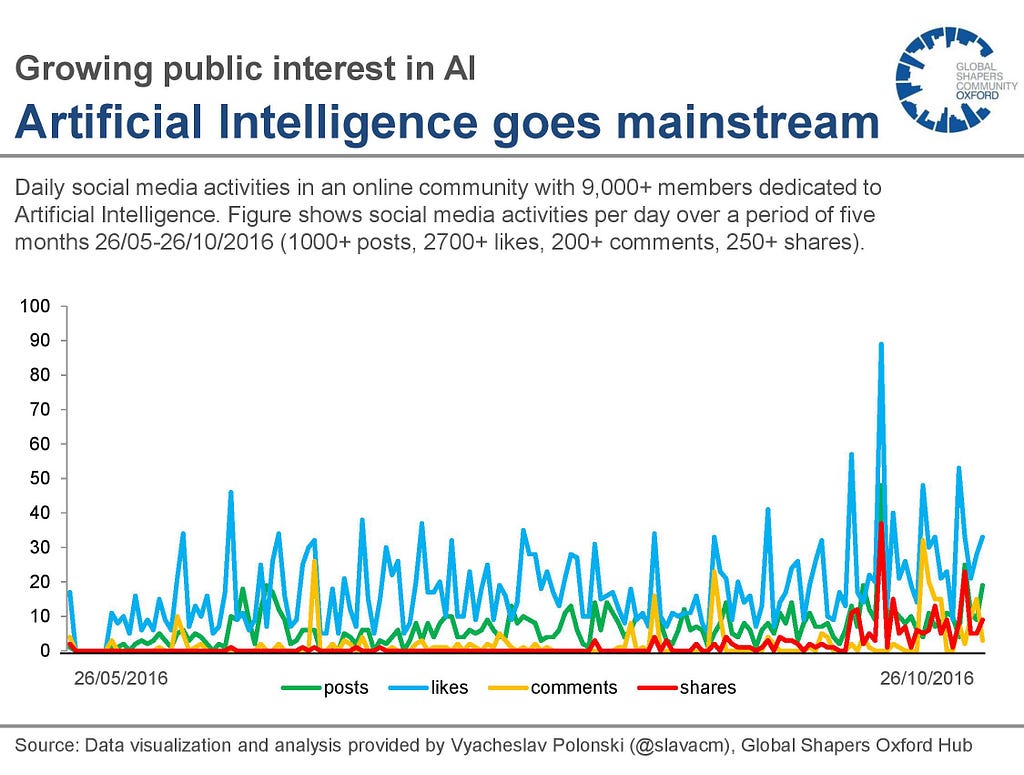
While personal AI assistants are already becoming a reality, to many it seems inconceivable that we would ever delegate such important civic duties — even if an AI assistant probably knows what’s best for us at any given moment. If fed enough data, an AI assistant could give recommendations that are far more accurate and personalized than we’d receive from even our closest friends.
Alphabet’s Chairman Eric Schmidt is convinced that advances in AI will make each and every human being in the world smarter, more capable and more accomplished. We’re already seeing the benefits of AI today. Take our smartphones where AI powers many of the features we use every day from translation to search. In the future, there is hope that AI can help society solve some of its toughest challenges, including climate change, population growth and human development.
Yet the intelligent potential of machines frequently elicits fear in people. Studies show that 34% of people are afraid of AI, while 24% think AI will be harmful for society. GWI finds that 63% of people worry about how their personal data is used by companies. Our own recent research at the Oxford Internet Institute shows that people hesitate to put their personal lives in the hands of an AI assistant, especially when that assistant makes decisions without providing a transparent reasoning for choosing one solution over a set of alternatives.
There is no need to confuse math with magic. AIs are not operated by small mystical creatures living inside your phones that have a sense of agency and their own agenda. But what we tend to forget is that the seemingly invisible mathematical models that make automated inferences about our interests, locations, behaviours, finances and health are designed by other humans using our pre-existing personal data.

Much of the current debate on algorithmic culture revolves around the role that humans play in the design of algorithms — that is, whether a creator’s subconscious beliefs and biases are encoded into the algorithms that make decisions about us. Journalism is replete with fears that developers willingly code their algorithms in a way that would permit subtle discrimination against certain groups of people over others — or worse, that technology platforms act as gatekeepers for the information that passes through them. As John Mannes writes, “A biased world can result in biased datasets and, in turn, bias artificial intelligence frameworks.”
The policy-makers and pundits advancing this argument tend to misconstrue the evidence for the apparent prevalence of algorithmic biases. They blame the people behind the algorithms, rather than the algorithms themselves. Finding fault in other people is, of course, the natural response, especially if you don’t understand the inner workings of the technologies at hand.
But algorithmic bias rarely originates from its human creators. In the majority of cases, it originates from the data that is used to train such algorithms. And this is, indeed, the real danger of the futuristic scenario described at the outset of this article.

Let’s pause for a moment and recall how machine learning actually works. By applying statistical learning techniques, we can develop computational models that can automatically identify patterns in the data. To accomplish that, the models need to be trained on large datasets to unearth boundaries and relationships in the data. The more data is used to train the model, the higher the predictive accuracy.
In the context of personalized digital applications, these statistical learning techniques are used to create an algorithmic identity for their users, which encompasses several dimensions, such as use patterns, tastes, preferences, personality traits and the structure of their social graph. This digital identity, however, is not directly based on users’ personhood or sense of self. Rather, such inferences are based on a collection of measurable data points and the machine’s interpretation thereof. In other words, the embodied user identity, no matter how complex, is replaced by an imperfect digital representation of itself in the eyes of the AI.
But the AI can only use historically traced data in its computations, which is then used to anticipate the users’ needs and make predictions about the future. This is why neural networks trained on images of past US presidents predicted Donald Trump would win the upcoming US election, after being trained with images of past (male) presidents. Since there were no female US presidents in the dataset, the AI was unable to deduce that gender was not a relevant characteristic for the model. In practice, if this particular AI were to elect the next president, it would vote for Trump.
These inferences result in increasingly deterministic recommendation systems, which tend to reinforce existing beliefs and practices similar to the echo chambers in our social media feeds. At this point, Jarno Koponen asserts that “personalization caricaturizes us and creates a striking gap between our real interests and their digital reflection”. Meanwhile, the authors of The Netflix Effect explain that personal recommendation systems tend to “steer the user towards this content, thus ghettoizing the user in a prescribed category of demographically classified content.” These aspects become more prevalent over time and it becomes evident why algorithmic determinism may be so harmful.

Our identities are dynamic, complex and contain many contradictions. Based on our social context, we may behave differently and require different forms of assistance from our AI agents — at school or at work, in a bar or in church.
Alongside our default self-presentation, there are many reasons why we may want to enact different identities to differentially engage with various sub-groups in our personal networks. Do we want to make ourselves socially accessible to our entire social network, or do we want to find new untapped social spaces away from the prying eyes of our friends and family? What happens if we want to experiment with different social roles and facets of our identity? As 4Chan founder Chris Poole a.k.a. moot says, “it’s not who you share with; it’s who you share as (…). Identity is prismatic; there are many lenses through which people view you”.
Distinguishing these different layers of self-presentation and mapping them onto various social environments is an extremely challenging task for an AI, which has been trained to serve a unique user identity. There are days when even we don’t know who we are. But our AI assistants will always have an answer for us: it’s who we were yesterday. Behaviour change becomes increasingly difficult, and our use patterns and belief systems run the risk of being locked up in a self-enforcing cycle — an algorithmic Groundhog Day.
The more we rely on personalized algorithms in everyday life, the more they will shape what we see, what we read, who we talk to, and how we live. By relentlessly focusing on the status quo, new recommendations on books to read, movies to watch and people to meet will give us more of the same things that have previously delighted us. This is what algorithmic determinism is all about.
When your past unequivocally dictates your future, personal development through spontaneity, open-mindedness and experimentation becomes more difficult. In this way, the notion of algorithmic determinism echoes what Winston Churchill once said about buildings: We shape our algorithms; thereafter, they shape us.

Today, real-world applications of AI are already embedded in almost every aspect of everyday life — and interest in the technology is growing. But there are two main challenges stopping the potential future outlined in the opening paragraphs.
In terms of technological progress, there is a lack of inter-operability standards for data exchange between applications, which prevents radical personalization. To be truly useful, machine learning systems require greater amounts of personal data — data that is currently siloed in proprietary databases of competing technology companies. Those who have the data hold the power. Some companies, most notably Apple and Viv, have started to democratize this power by experimenting with third-party service integration. Most recently, some of the largest technology companies announced a major partnership to collaborate on AI research that benefits the many, not the few. Going forward, this will be crucial to establishing public trust in AI.
In terms of social progress, there is an implicit aversion to the rapid growth of AI. People are afraid of losing control of their AI assistants. Trust is a direct function of our ability to control something. Putting their relationships and reputation on the line for a seemingly marginal improvement in productivity is not something most people are willing to do.
Of course, in its early stages, an AI assistant can behave in ways that its human creators might not expect. There are plenty of precedents of failed AI experiments that have diminished trust in narrow AI solutions and conversational bots. When Facebook, Microsoft and Google all launched their bot platforms in 2016, users were disappointed with the limited usefulness, application and customization of the prematurely presented AI technologies.
The lingering fears about the ramifications of AI technology have also been fuelled by the many dystopian sci-fi scenarios that have depicted sentient rogue AIs taking over the world. But the future we’re heading towards will be neither Skynet nor Orwellian Big Brother: it is much more likely to look like the hedonic society portrayed in A Brave New World, where technologies maintain the status quote through a regime of universal happiness and pervasive self-indulgence.

Technologies keep marching ahead, but there’s also hope. The 2016 annual survey of the Global Shapers Community revealed that young people see AI as the main technological trend. What is more, 21% of respondents say they support rights for humanoid robots, with this support disproportionately higher in South-East Asia, where young people appear to have a more favourable attitude towards the role of AI in everyday life.
In Europe, the European Union’s new General Data Protection Regulation could restrict extreme forms of algorithmic determinism by giving users the opportunity to ask for an explanation of particular profiling-based algorithmic decisions. This law is expected to be implemented in all EU member states by May 2018. While this regulation restricts profiling and underlines the pressing importance of human interpretability in algorithm design, it is uncertain whether it will result in any major changes to the prevailing algorithmic practices of large technology companies.
Thousands of algorithmic decisions are made about each of us every day — ranging from Netflix movie recommendations and Facebook friend suggestions to insurance risk assessments and credit scores. All things considered, are citizens themselves now responsible for keeping track of and scrutinizing the algorithmic decisions made about them, or is this something that needs to be encoded into the designs of the digital platforms they’re using? Accountability is an important issue here, precisely because it is so difficult to measure and implement on a large scale.
Thus the question we ought to ask ourselves before leaping headlong into the unknown is what do we want the relationship between humans and AI to look like? Rethinking these issues will hopefully allow us to design non-deterministic, transparent and accountable algorithms that recognize the complex, evolving and multifaceted nature of our individuality.
About the author: Vyacheslav (@slavacm) is a doctoral candidate at the Oxford Internet Institute, researching complex social networks, digital identity and technology adoption. He has previously studied at Harvard University, Oxford University and the London School of Economics and Political Science. Vyacheslav is actively involved in the World Economic Forum and its Global Shapers community, where he is the Curator of the Oxford Hub. He writes about the intersection of sociology, network science and technology.
Originally published on the World Economic Forum Agenda Blog and TechCrunch before the US Election Day 2016. Thanks to Bernie Hogan, Phil Howard and Jonathan Zittrain for the helpful comments and ideas for this piece!
If you enjoyed this post, please hit the tiny “heart” button, leave a comment below or share this post with your friends and colleagues. Thank you!