30 Jul 2014
 In this series of blog posts, we are documenting the process by which a group of computer and social scientists are working together on a project to understand the geography of Wikipedia citations. Our aim is not only to better understand how far Wikipedia has come to representing ‘the sum of all human knowledge’ but to do so in a way that lays bare the processes by which ‘big data’ is selected and visualized. In this post, I outline the way we initially thought about locating citations and Dave Musicant tells the story of how he has started to build a foundation for coding citation location at scale. It includes feats of superhuman effort including the posting of letters to a host of companies around the world (and you thought that data scientists sat in front of their computers all day!)
In this series of blog posts, we are documenting the process by which a group of computer and social scientists are working together on a project to understand the geography of Wikipedia citations. Our aim is not only to better understand how far Wikipedia has come to representing ‘the sum of all human knowledge’ but to do so in a way that lays bare the processes by which ‘big data’ is selected and visualized. In this post, I outline the way we initially thought about locating citations and Dave Musicant tells the story of how he has started to build a foundation for coding citation location at scale. It includes feats of superhuman effort including the posting of letters to a host of companies around the world (and you thought that data scientists sat in front of their computers all day!)
Many articles about places on Wikipedia include a list of citations and references linked to particular statements in the text of the article. Some of the smaller language Wikipedias have fewer citations than the English, Dutch or German Wikipedias, and some have very, very few but the source of information about places can still act as an important signal of ‘how much information about a place comes from that place‘.
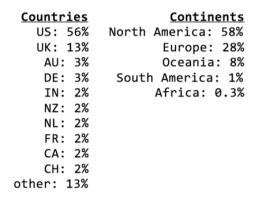
When Dave, Shilad and I did our overview paper (‘Getting to the Source‘) looking at citations on English Wikipedia, we manually looked up the whois data for a set of 500 randomly collected citations for articles across the encyclopedia (not just about places). We coded citations according to their top-level domain so that if the domain was a country code top-level domain (such as ‘.za’), then we coded it according to the country (South Africa), but if it was using a generic top-level domain such as .com or.org, we looked up the whois data and entered the country for the administrative contact (since often the technical contact is the domain registration company often located in a different country). The results were interesting, but perhaps unsurprising. We found that the majority of publishers were from the US (at 56% of the sample), followed by the UK (at 13%) and then a long tail of countries including Australia, Germany, India, New Zealand, the Netherlands and France at either 2 or 3% of the sample.

Geographic distribution of English Wikipedia sources, grouped by country and continent. Ref: ‘Getting to the Source: Where does Wikipedia get its information from?’ Ford, Musicant, Sen, Miller (2013).
 This was useful to some extent, but we also knew that we needed to extend this to capture more citations and to do this across particular types of article in order for it to be more meaningful. We were beginning to understand that local citations practices (local in the sense of the type of article and the language edition) dictated particular citation norms and that we needed to look at particular types of article in order to better understand what was happening in the dataset. This is a common problem besetting many ‘big data’ projects when the scale is too large to get at meaningful answers. It is this deeper understanding that we’re aiming at with our Wikipedia geography of citations research project. Instead of just a random sample of English Wikipedia citations, we’re going to be looking up citation geography for millions of articles across many different languages, but only for articles about places. We’re also going to be complementing the quantitative analysis with some deep dive qualitative analysis into citation practice within articles about places, and doing the analysis across many language versions, not just English. In the meantime, though, Dave has been working on the technical challenge of how to scale up location data for citations using the whois lookups as a starting point.
This was useful to some extent, but we also knew that we needed to extend this to capture more citations and to do this across particular types of article in order for it to be more meaningful. We were beginning to understand that local citations practices (local in the sense of the type of article and the language edition) dictated particular citation norms and that we needed to look at particular types of article in order to better understand what was happening in the dataset. This is a common problem besetting many ‘big data’ projects when the scale is too large to get at meaningful answers. It is this deeper understanding that we’re aiming at with our Wikipedia geography of citations research project. Instead of just a random sample of English Wikipedia citations, we’re going to be looking up citation geography for millions of articles across many different languages, but only for articles about places. We’re also going to be complementing the quantitative analysis with some deep dive qualitative analysis into citation practice within articles about places, and doing the analysis across many language versions, not just English. In the meantime, though, Dave has been working on the technical challenge of how to scale up location data for citations using the whois lookups as a starting point.
[hands over the conch to Dave…]
In order to try to capture the country associated with a particular citation, we thought that capturing information from whois databases might be instructive since every domain, when registered, has an administrative address which represents in at least some sense the location of the organization registering the domain. Though this information would not necessarily always tell us precisely where a cited source was located (when some website is merely hosting information produced elsewhere, for example), we felt like it would be a good place to start.
To that end, I set out to do an exhaustive database lookup by collecting the whois administrative country code associated with each English Wikipedia citation. For anyone reading this blog who is familiar with the structure of whois data, this would readily be recognized as exceedingly difficult to do without spending lots of time or money. However, these details were new to me, and it was a classic experience of me learning about something “the hard way.”
I soon realised how difficult it was going to be to obtain the data quickly. Whois data for a domain can be obtained from a whois server. This data is typically obtained interactively by running a whois client, which is most commonly either a command-line program or alternatively served through a whois client website. I found a Python library to make this easy if I already had the IP addressed I needed, and so I discovered, in initial benchmarking, that I could run about 1,000 IP-address-based whois queries an hour. That would make it exceedingly slow to look up the millions of citations in English Wikipedia, before even getting to other language versions. I later discovered that most whois servers limit the number of queries that you can make per day, and had I continued along this route, I undoubtedly would have been blocked from those servers for exceeding daily limits.
The team chatted, and we found what seemed to be some good options for doing bulk whois results. We found web pages of the Regional Internet Registry (RIR) ARIN, which has a system whereby researchers are able to request access to their entire database after filling out some forms. Apart from the red tape (the forms had to be mailed in by postal mail), this sounded great. I then discovered that ARIN and the other RIRs make the entire dump of the IP addresses and country codes that they allocate available publicly, via FTP. ‘Perfect!’ I thought. I downloaded this data, and decided that since I was already looking up the IP addresses associated with the Wikipedia citations before doing the whois queries, I could then look up those IP addresses in the bulk data available from the RIRs instead.
Now that I had a feasible plan, I then proceeded to write more code to lookup IP addresses for the domains in each citation. This was much faster, as domain-to-IP lookups are done locally, at our DNS server. I could now do approximately 600 lookups a minute to get IP addresses, and then an effectively instant lookup for country code on the data I obtained from the RIRs. It was then pointed out to me, however, that this approach was flawed because of content distribution networks (CDNs), such as Akamai. Many large- and medium-sized companies use CDNs to mirror their websites, and when you do a lookup on domain to get IP address, you get the IP address of the CDN, not of the original site. ‘Ouch!’ This approach would not work…
I next considered going back to the full bulk datasets available from the RIRs. After filling out some forms, mailing them abroad, and filling out a variety of online support requests, I finally engaged in email conversations with some helpful folks at two of the RIRs who told me that they had no information on domains at all. The RIRs merely allocate ranges of IP address to domain registrars, and they are the ones who can actually map domain to IP. It turns out that the place to find the canonical IP address associated with a domain is precisely the same place as I would get the country code I wanted: the whois data.
Whois data isn’t centralized – not even in a few places. Every TLD essentially has its own canonical whois server, each one of which reports the data back in its own different natural-text format. Each one of those servers limits how much information you can get per day. When you issue a whois query yourself, at a particular whois server, it in turn passes the query along to other whois servers to get the right answer for you, which it passes back along.
There have been efforts to try to make this simpler. The software projects, ruby-whois and phpwhois implement a large number of parsers designed to cope with the outputs from all the different whois servers, but you still need to be able to get the data from them without being limited. Commercial providers will provide you bulk lookups at a cost – they must query what they can at whatever speed they can, and archive the results. But they are quite expensive. Robowhois, one of the more economical bulk providers, asks for $750 for 500,000 lookups. Furthermore, there is no particularly good way to validate the accuracy or completion of their mirrored databases.
It was finally proposed that maybe we could do this ourselves by the use of parallel processing, using multiple IP addresses ourselves so as to not get rate limited. I began looking into that possibility but it was only then that I realized that many of the whois providers don’t ever really use country codes at all in the results of a whois query. At the time I’m writing this, none of the following queries return a country code:
whois news.com.au
whois pravda.ru
whos gov.br
whois thestar.com.my
whois jordan.gov.jo
whois english.gov.cn
whois maroc.ma
So after all that, we’ve landed in the following place:
– Bulk querying whois databases is exceedingly time consuming or expensive, with challenges in getting access to servers blocked.
– Even if the above problems were solved, many TLDs don’t provide country code information on a whois lookup, which would make doing an exhaustive lookup pointless because it would unbalance the whole endeavor towards those domains where we could get country information.
– I’m a lot more knowledgeable than I was about how whois works.
So, after a long series of efforts, I found myself dramatically better educated about how whois works; and in much better shape to understand why obtaining whois data for all of the English Wikipedia citations is so challenging.