Twitter has rolled out a limited trial of 280 characters for some of its users. In announcing the trial, Twitter specifically noted that most Japanese tweets had 15 characters while most English tweets had 34 characters. They also noted that only 0.4% of Japanese tweets hit the 140-character limit whereas 9% of English tweets do.
How differences in the information density of languages leads to different user experiences on Twitter is something I published on in 2015 with Han-Teng Liao and King-wa Fu and also a question that researchers at the Nara Institute of Science and Technology (NAIST) investigated from a different prospective.
Ostensibly Twitter launched with a 140-character limit to allow tweets to be “consumed easily anywhere, even via mobile text messages” (SMS). Of course, text messages have a byte limit, not a character limit; so, tweets only ever fit within one text message for a small number of languages. Furthermore, what seemed like a universal design choice—140 characters—actually has rather different effects in different languages. These differences are most pronounced for Japanese and Chinese, and Twitter has done particularly well in Japan, a success it wants to replicate in more locations.
There are a number of ways we can measure how much information is conveyed by one character. Regardless of the measure, however, it is clear that a language like Japanese contains more information per character than English (e.g., 政治 vs. politics). In our research, we used translations of TED talks to arrive at a figure of one Japanese character approximating 2.5 English characters (and one traditional Chinese character approximating 3.2 English characters). That isn’t the whole story, however, because the amount of information in a tweet is also a function of its length, and tweets in Japanese and Chinese tend to have fewer characters than English tweets. Nonetheless, we do find that tweets in Japanese and Chinese tend to have more information content than tweets in English on average. Twitter’s move to double the amount of characters for languages other than Chinese, Japanese, and Korean (CJK) while somewhat arbitrary should allow more than enough space to fit the information content of the average Japanese or Chinese tweet in English.
The big question for Twitter is whether the move will increase use of and engagement with the platform. Here, unfortunately, there is a lot more than the character limit at play. Japan has long been an outlier in technology use, leading to what the Japanese have dubbed the Galápagos effect (ガラパゴス化). Its mobile phones had email in 1999, cameras in 2000, 3G in 2001, music downloads in 2002, e-money in 2004, and digital TV in 2005—all long before other markets.
Twitter was embraced quickly in the country and Japanese users of Twitter form a dense, but isolated, portion of the Twitter network. Japanese also stands out as a unique language community on TripAdvisor, Wikipedia (in terms of article creation by anonymous users, bilingualism, and content differences [pdf]), and other platforms. Ultimately, the use of a given technology is a function not only of its user experience (which Twitter can shape as it has with the character limit), but also many elements of culture that are beyond the control of the company.
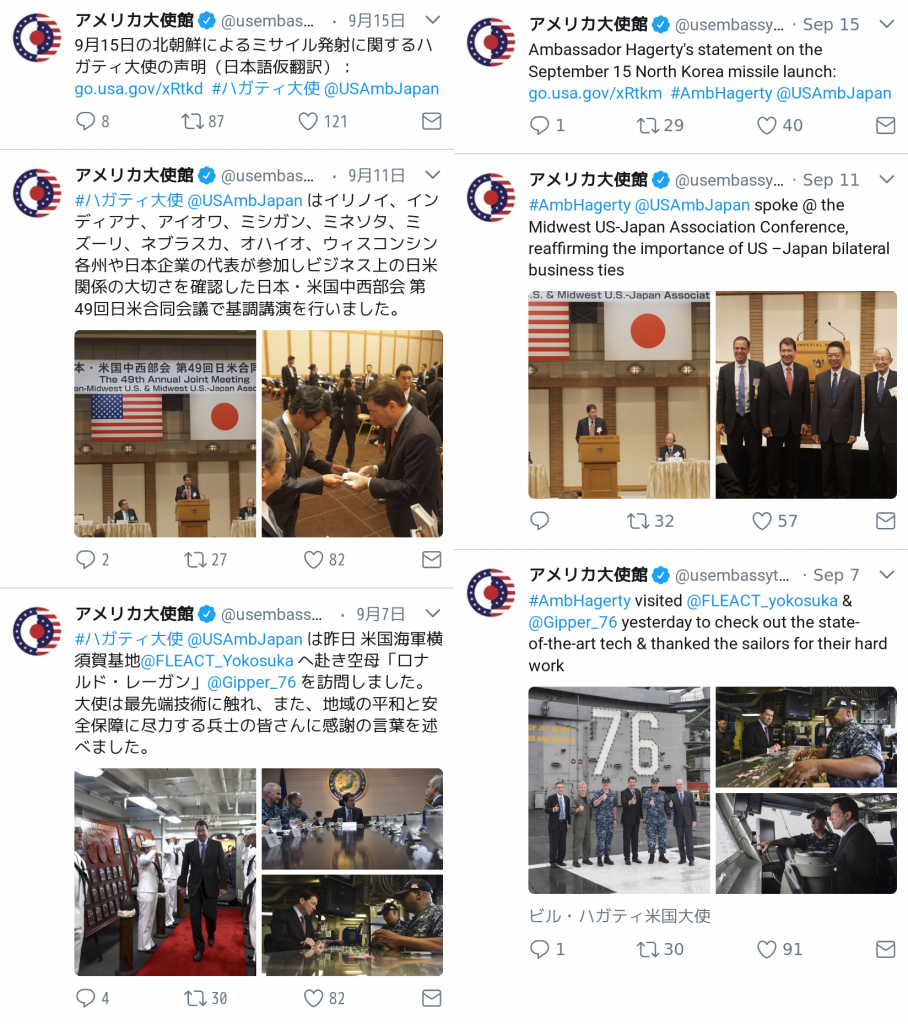
Similar tweets from @usembassytokyo in Japanese and English. The embassy often includes more detail/explanation in its Japanese-language tweets.
Even within a single language, Twitter is supporting a number of different use cases simultaneously (staying in touch with friends, following news, co-experiencing a live event or conference, etc.). More characters will enhance some of these, be unimportant to others, and perhaps detract from still others. There simply is not a single technological fix that will enhance everyone’s experience across languages and use cases. One possible character-related change is adding a “soft limit”—showing only the first X characters of a tweet by default and providing a “…more” link that can be clicked to show the rest of the tweet. This would balance the compact display of tweets, encourage users to strive for conciseness, and yet also accommodate use cases where more information is truly needed.
